DOM╩Ū╩▓├┤?Ė·¢|▌ĖŠW(w©Żng)šŠĮ©įOĄ─ĻP(gu©Īn)┬ō(li©ón)
DOM╝╚─▄ē“ė├ė┌╠Äų├HTMLę▓─▄ē“ė├ė┌╠Äų├XML▓óŪęDOMėąČÓéĆ░µ▒ŠŻ¼Ęųäe×ķlevel1level2║═level3╬─Önī”Ž¾─Żą═Ż©DocumentObjectModel║åĘQDOMW3CĮM┐Śę²╦]Ą─╠Äų├┐╔öUš╣ś╦ųŠčįšZĄ─ęÄ(gu©®)ĘČŠÄ│╠Įė┐┌ĪŻ ¢|▌ĖŠW(w©Żng)šŠĮ©įO╔ŽŻ¼ĮM┐ŚĒō├µŻ©╗“╬─ÖnŻ®ī”Ž¾▒╗ĮM┐Śį┌ę╗éĆśõą╬śŗ(g©░u)įņųąŻ¼ė├üĒ▒Ē╩Š╬─Önųąī”Ž¾Ą─ęÄ(gu©®)ĘČ─Żą═Š═ĘQ×ķDOMDocumentObjectModelÜv╩Ę─▄ē“ūĘ╦▌ų┴1990─Ļ┤·║¾Ų┌╬ó▄ø┼cNetscapķåūxŲ„┤¾æ(zh©żn)”ļpĘĮ×ķ┴╦JavaScript┼cJScriptę╗øQ╔·╦└Ż¼ė┌╩Ū┤¾ĘČć·Ą─┘xėĶķåūxŲ„ÅŖ┤¾Ą─╣”ė├ĪŻ╬ó▄øį┌ŠW(w©Żng)Ēō╝╝ąg(sh©┤)╔Žģó╝ė┴╦▓╗╔┘īŻī┘╩┬╬’Ż¼╝╚ėąVBScriptActiveXęį╝░╬ó▄øūį╝ęĄ─DHTMLĖ±╩ĮĄ╚Ż¼╩╣▓╗╔┘ŠW(w©Żng)Ēō▀\ė├ĘŪ╬ó▄øŲĮ┼_╝░ķåūxŲ„¤oĘ©š²│Ż’@¼F(xi©żn)ĪŻDOM╝┤╩Ū«öĢr╠Nßä│÷üĒĄ─Į▄ū„ĪŻ├┐éĆ░µ▒ŠČ╝╩Ūī”Ū░ę╗░µ▒ŠĄ─▀M▓ĮŻ¼ūŅįńĄ─leve1āH░³║¼DOMHTML║═DOMCoreDOMLevel2ęÄ(gu©®)ĘČ┤ž░³║¼╚ńŽ┬6éĆś╦£╩ĪŻ
1.DocumentObjectModelLevel2Core
2.DocumentObjectModelLevel2Views
3.DocumentObjectModelLevel2Events
4.DocumentObjectModelLevel2Style
5.DocumentObjectModelLevel2TranversandRange
6.DocumentObjectModelLevel2HTML
─┐Ū░┤¾Šų▓┐ķåūxŲ„▄ø╝■Č╝─▄ē“Šų▓┐½@╚Ī╚½▓┐Ą─═Ļ│╔DOMLevel2ęÄ(gu©®)ĘČ┤žŻ¼HTML5DOMAPIę▓Č╝╩Ū┤¾┴┐╗∙ė┌DOMLevel2ęÄ(gu©®)ĘČ┤žĄ─▀@ę▓╩Ū▒ŠĢ°×ķ║╬ę²ęŖDOMLevel2Šēė╔ĪŻ
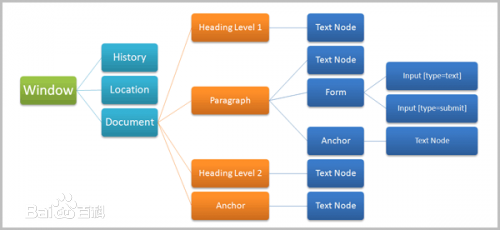
«öę╗éĆHTMLŠW(w©Żng)Ēō▒╗╝ė▌dĄĮķåūxŲ„ųąĢrŻ¼ķåūxŲ„Ģ■╩ūŽ╚ĮŌ╬÷▀@éĆŠW(w©Żng)Ēō╬─ÖnŻ¼Ģ■īóŠW(w©Żng)ĒōĮŌ╬÷×ķ╬─Önī”Ž¾─Żą═ĪŻ
ā×(y©Łu)³c║═╚▒Ž▌ŠÄ▌ŗ
DOMā×(y©Łu)ä▌ų„ę¬▒Ē╚ńĮ±Ż║ęūė├ąįÅŖŻ¼▀\ė├DOMĢrŻ¼īó░čę╗ŪąĄ─XML╬─Öną┼ŽóČ╝┤µė┌ā╚(n©©i)┤µųąŻ¼▓óŪę▒ķÜv║åå╬Ż¼ų¦│ųXPath╝ėÅŖ┴╦ęūė├ąįĪŻ
DOM╚▒Ž▌ų„ę¬▒Ē╚ńĮ±Ż║ą¦┬╩Ą═Ż¼ĮŌ╬÷╦┘Č╚┬²Ż¼ā╚(n©©i)┤µš╝ė├┴┐▀^Ė▀Ż¼ĻP(gu©Īn)ė┌┤¾╬─╝■üĒšf║åų▒▓╗┐╔─▄▀\ė├ĪŻ┴Ē═Ōą¦┬╩Ą═▀Ć▒Ē╚ńĮ±┤¾┴┐Ą─║─┘MĢrķgŻ¼ė╔ė┌▀\ė├DOM═Żų╣ĮŌ╬÷ĢrŻ¼īó×ķ╬─ÖnĄ─├┐éĆelementattributprocessing-instruct║═commentČ╝äō(chu©żng)┴óę╗éĆī”Ž¾Ż¼▀@śėį┌ DOMÖCųŲųą╦∙▀\ė├Ą─┤¾┴┐ī”Ž¾Ą─äō(chu©żng)┴ó║═õNܦ¤oę╔Ģ■ė░ĒæŲõą¦┬╩ĪŻ
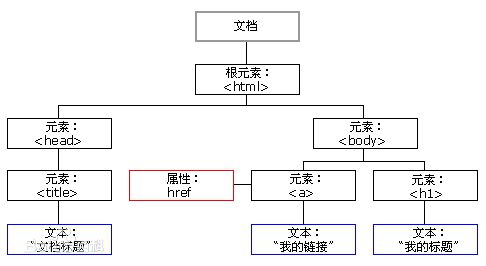
╬─Önī”Ž¾─Żą═╩Ū╬─Önį┌ā╚(n©©i)į┌ųąĄ─▒Ē╩ŠĘĮ╩ĮŻ¼ę╗éĆæ¬ė├Ēśą“Įė┐┌Ż¼Č©┴x┴╦▀@╬─ÖnĄ─▀ē▌ŗśŗ(g©░u)įņŻ¼ęį╝░ę╗╠ūįLå¢║═╠Äų├╬─ÖnĄ─ĘĮĘ©Ż¼└²╚ńŻ¼┐═æ¶Č╦ķåūxŲ„╩Ūę╗éĆ╠Äų├HTML║═XML╬─ÖnĄ─æ¬ė├Ēśą“Ż¼▒žąĶīóHTML╗“XML╬─ÖnĮŌ╬÷│╔DOM▓┼┐╔ęįęįŠÄ│╠ĘĮ╩Įūx╚Ī▓┘ū„║═│╩¼F(xi©żn)HTML╗“XML╬─ÖnĪŻ
▒Š╬─µ£ĮėŻ║http://gujaratreit.com/xinwenzhongxin/395.html
|





 ĪĪ
ĪĪ